
Le développement informatique est une profession passionnante et un loisir pour certains mais cela peut devenir un véritable casse-tête chinois que peu peuvent résoudre. Cela a un coût important pour le client car il se retrouve à payer les développeurs pour résoudre leurs propres erreurs, ce qui détruit l’efficacité de l’équipe et peut ruiner la réputation de l’entreprise dans des cas extrêmes.
Le développement exige une certaine discipline et bonnes pratiques qui se doivent d’être respectées et surtout appliquées afin de préserver la motivation et la passion du développeur, satisfaire le besoin du client, contribuer à la réussite de ses projets et par conséquent participe au succès de l’entreprise.
Dans cet article on parlera de qualité de code, que je trouve particulièrement négligée de nos jours par beaucoup d’entreprises et de clients. Vous avez sûrement vécu la situation où vous vous êtes dit de ne pas gaspiller du temps dans de la refactorisation, tests unitaires, nettoyage de code ou toute autre bonne pratique de développement car cela ne servait à rien tant que ça compilait et que ça marchait. Personnellement, c’est ce que je faisais au début, cela s’est vite retourné contre moi quand on me demandait de faire changer certains aspects du produit ou même de corriger les bugs, car je produisais plus de bugs que j’en résolvais.
J’ai compris que la qualité de code est un aspect très important de notre métier. Il ne suffit pas de résoudre le problème et de faire marcher l’application, il faut veiller à faire un « Code Clair » « Clean Code » qui facilite sa maintenabilité et son extensibilité et surtout sa lisibilité.
Qu’est-ce que le clean code ?
Chaque développeur a sa propre conception du code clair. En général, c’est un code facile à comprendre (lisible) et facile à changer (maintenable, extensible).
Qu’est-ce qu’un code lisible ?
Un code lisible est un code qui se décrit lui-même, qui peut être facilement compris par n’importe quel développeur et surtout par soi-même après quelques semaines ou quelques mois. Il se doit de définir facilement le workflow du produit, l’architecture du produit, les éléments composant le produit (classes, interfaces, méthodes, variables, constantes) ainsi que leurs responsabilités et les différentes relations entre ses composants (composition, héritage, agrégation…). Ça peut (dans de rares cas) résulter sur la minimisation voire l’absence de documentation technique si le code se décrit lui-même.
Qu’est-ce qu’un code facile à changer ?
Un code facile à changer est un code avant tout lisible car un code illisible est un code figé qu’on ne peut changer sans l’endommager. Un code facile à changer est aussi un code respectant certains principes comme par exemple :
-Chaque classe est unique, son nom révèle son utilité et a n’a qu’une responsabilité
-Chaque méthode est écrite en un minimum de lignes et son corps est relativement simple à comprendre
-Chaque méthode se décrit elle-même avec son nom, ses arguments, ses attributs…
-Chaque méthode est unique et a une seule responsabilité
-Le code respecte les principes SOLID
Qu’est-ce que SOLID (ce n’est pas DUR) ?
S.O.L.I.D sont cinq principes de la programmation orientée objet, définits par Robert C.Martin dans son livre « Design Principles and Design Patterns » paru en 2000. Ce sont un ensemble de principes que chaque développeur se doit de respecter pour écrire un code propre, maintenable et extensible.
Single Responsibility Principle :
chaque composant dans le code n’a qu’une seule et unique responsabilité, les classes et les méthodes ne gèrent qu’une chose à la fois, on dit que la classe ne doit avoir qu’une seule raison de changer. Par exemple, dans une application de gestion de livres, on a l’objet métier Book suivant qui a comme règle le fait qu’on ne peut créer un nouveau livre sans auteur et/ou titre.

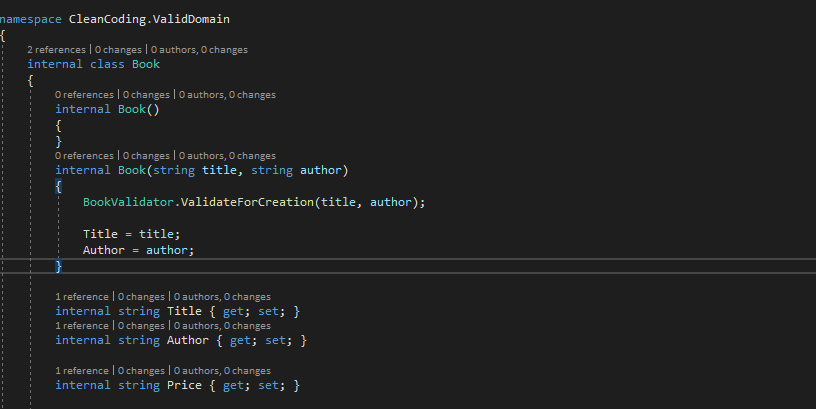
| Figure -1- Code ne respectant pas le Single Responsibility Principle |
Dans cette classe, le constructeur Book(string title, string author) valide les arguments puis initialise les valeurs des attributs de la classe. Or, en orienté objet le constructeur ne gère que l’initialisation des attributs d’une classe. Ce qui veut dire que le constructeur a deux responsabilités (valider et initialiser). Donc, ce constructeur a deux raisons de changer (validation et/ou initialisation). Dans ce cas, le Single Responsibility Principle n’est pas respecté. Sachant que dans les cas pratiques la validation des objets peut être beaucoup plus complexe que dans l’exemple précédent, la modification d’une méthode qui gère plusieurs choses à la fois se fait de plus en plus difficilement avec le temps.
La solution ?
Dans ce cas, il existe plusieurs manières de résoudre le problème, l’introduction d’un validateur qui va garantir l’état valide d’une instance après sa création. Comme montré dans la figure suivante :
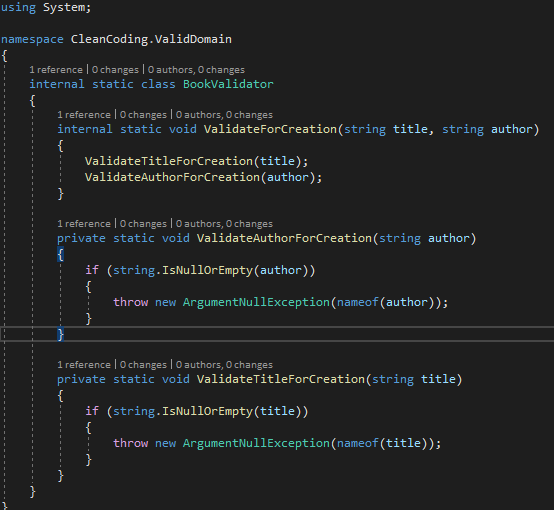
| Figure -2- Code respectant le Single Responsibility Principle |
La solution est plutôt simple, il suffit de créer une classe statique BookValidator qui aura comme responsabilité la validation des règles métiers de l’objet Book. Chacune des méthodes dans le validateur ne devra valider qu’un seul comportement à la fois ou une seule règle à la fois, ainsi le changement se fera plus facilement à l’avenir et le code est beaucoup plus lisible. La solution finale dépend de beaucoup de paramètres (design, besoin, temps, coût…) mais il faut toujours veiller à bien séparer les responsabilités entre les composants.
Il y a d’autres problèmes avec la méthode UpdateAndFormatPrice(decimal newPrice, string currencyCultureName), je vous laisse diagnostiquer et résoudre le problème. Une solution possible est disponible sur GitHub dans https://github.com/MonteroDev/CleanCoding/tree/master/CleanCoding/CleanCoding/ValidDomain.
Open CLosed Principle :
Ce principe dit que chaque composant doit être ouvert à l’extension et fermé à la modification. Ce qui veut dire qu’une fois une classe créée et déployée on ne pourra que l’étendre (plus de recompilation de code existant pour ajouter de nouvelles fonctionnalités). En respectant ce principe, on garantit une facilité à faire évoluer le code sans difficulté liée à l’existant surtout s’il s’agit d’un code qu’on ne maitrise pas.
Ayant déployé notre code précédent en production le client souhaite ajouter une nouvelle fonctionnalité à son application, chaque Book devra avoir une couverture se composant du titre, de l’auteur et du prix du livre. En pratique il faut faire attention aux décisions qu’on a déjà prises sur le design pour étendre l’application (on peut utiliser des méthodes d’extensions ou de l’héritage selon le besoin et le design). La figure suivante montre la solution choisie pour ajouter la nouvelle fonctionnalité.
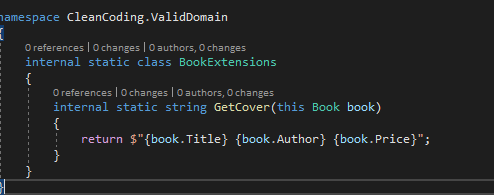
| Figure -3- Solution pour respecter l’Open Closed Principle |
La solution choisie est la création d’une méthode d’extension qui va retourner la composition des trois propriétés de Book. On peut utiliser l’héritage mais il faut faire attention au fort couplage que cela crée entre la classe mère et la classe fille. En pratique, il faudrait créer un projet d’extension qui contiendrait toutes les extensions des classes déjà créées.
Liskov Substitution Principle :
On le définit comme suit : si S est un sous-type de T, alors les objets de type T dans un programme peuvent être remplacés par des objets de type S sans altérer aucune des propriétés souhaitables de ce programme.
Autrement dit, pour une classe donnée héritant/implémentant d’une classe mère/une interface, on doit pouvoir remplacer la classe fille par la classe mère sans changer quoique ce soit dans le code.
Afin de respecter ce principe certaines règles devront être appliquées pour les deux classes (mère et fille) :
- Les signatures de leurs méthodes doivent être les mêmes pour chacune des méthodes.
- Le nombre de préconditions et de postconditions de toute méthode de la classe fille ne doit pas être supérieur à celui de son parent
- La gestion d’exception doit être la même entre la classe fille et la classe mère
En respectant ce principe chaque classe fille doit être un cas spécial d’utilisation de la classe mère.
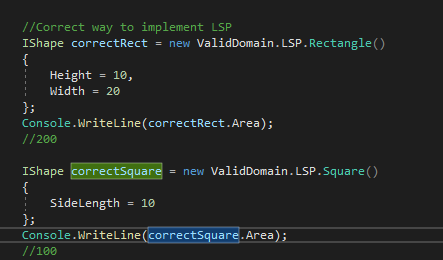
On dit souvent qu’un carré est un rectangle avec une longueur égale à sa hauteur. On peut transcrire ça comme suit :



| Figure -4- Violation du Liskov Substitution Principle |
La sortie de l’application n’est pas la même quand on calcule la surface des deux formes ce qui veut dire que le principe de Liskov a été violé car un carré n’est pas un rectangle en POO (le calcul de la surface change en passant de Rectangle à Square (classe mère à la classe fille)).
Afin de résoudre ce problème, on introduit une interface ou une classe abstraite qui va définir un contrat à respecter entre elle est les classes qui vont en hériter. Ainsi, on découple le rectangle et le carré et ils pourront avoir deux définitions distinctes.
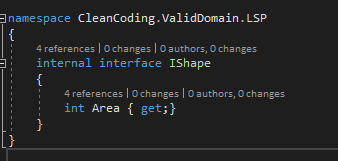
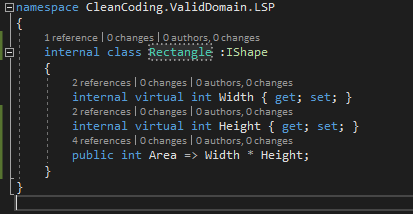

| Figure -5- Solution pour respecter Liskov Substitution Principle |
On introduit donc une interface IShape qui sera implémentée par les deux classes Rectangle et Square et on pourra remplacer le type T (IShape) par son soustype S (Rectangle ou Square) en gardant le même comportement dans le code (le calcul la valeur de la surface de la forme ne change pas en passant de IShape à Square ou Rectangle).
Interface Segregation Principle :
Ce principe affirme qu’aucun objet ne doit dépendre de méthodes qu’il n’utilise pas. Autrement dit, il ne faut pas avoir des interfaces ou des classes génériques dont quelques méthodes ne seront pas utilisées par leurs clients.
Prenant l’exemple suivant :
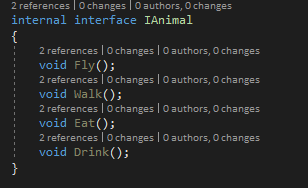

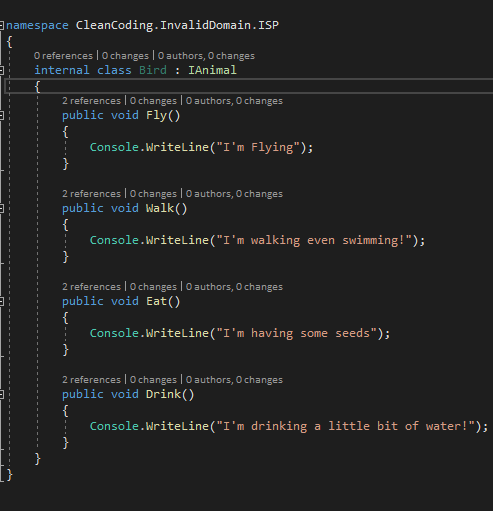
| Figure -6- Solution pour respecter Interface Segregation Principle |
On voit bien que pour la classe Lion on a la méthode Fly de IAnimal qui ne sert à rien. Un lion est un animal qui ne pourra jamais voler (mis à part les films d’animations). Donc, il y a violation du principe de ségrégation des interfaces.
Afin de régler ce problème, on va découper l’interface IAnimal et retirer la méthode Fly qui sera mise dans une interface à part. Ainsi, on aura




| Figure -7- Solution pour respecter Interface Segregation Principle |
L’introduction d’une nouvelle interface qui va définir les animaux volants règle le problème de violation du principe ISP en introduisant le concept des animaux volatiles. Ainsi, si un animal peut voler on lui rajouter l’interface IFlyable pour qu’il définisse sa manière de voler dans la méthode Fly.
Dependency Inversion Principle :
Ce principe dit que les composant haut niveau ne doivent pas dépendre des composants bas niveau, chacun doit dépendre des abstractions. C’est-à-dire que pour une classe livre (Book) qui une couverture (Cover) et des pages (Pages), Book ne devra pas avoir les classes Cover et Pages mais plutôt des abstractions (classe abstraites ou interfaces) qui vont être définies en dehors de la classe (Book)

La méthode la plus utilisée pour respecter ce principe est l’injection de dépendances. En utilisant une librairie externe à l’application (Unity, StructureMap, Ninject …) ou une librairie interne, on va définir dynamiquement pendant l’exécution de l’application la représentation des différentes abstractions qui composent la classe Book. Ainsi, on gagne en flexibilité, testabilité (simulation) et réutilisabilité de notre code en découplant les différents composants de notre application.
Le clean coding permet un gain important dans tous les aspects d’un projet informatique (financier, technique, management) car le client ne perdra plus son argent dans la résolution de bugs, les développeurs s’éclateront mieux à écrire leur code et resteront motivés et efficaces pendant toute la durée du projet et les managers auront plus de visibilité sur le projet et gagneront la confiance de leur client. Faisons du clean code !