
Elasticsearch est un moteur de recherche assez puissant ayant une fonctionnalité en particulier qui le distingue des autres solutions du monde NoSQL : la possibilité de pouvoir visualiser des données de manière visuelle. Cette fonctionnalité est très demandée par les data-scientist. La visualisation de données permet de répondre aux besoins métier en fonction des données récoltées. Vous l’aurez devinez! C’est bien-sûr pour répondre à ce besoin que le client Kibana a été développé !
Kibana est un outil graphique, conçu pour explorer des données stockées dans elasticsearch de manière visuelle. Ce client peut être branché sur n’importe quel cluster elasticsearch.
Dans cet article, nous commencerons par une brève parenthèse sur elasticsearch et ses principes, puis nous découvrirons l’outil kibana, de son installation à son usage pour l’exploration des données et l’analyse de logs.
Zoom sur Elasticsearch.
Le moteur de recherche
Comme tout moteur de recherche, elasticsearch procède par trois grandes phases :
- Le CRAWL : c’est le nom désigné pour l’action des robots dans une page web. En somme, les robots visitent un domaine, et suivent les liens qui s’y trouvent afin de découvrir d’autres pages.
- l’INDEXATION : permet de stocker et organiser le contenu trouvé pendant la phase de crawl.Une fois une page indexée, elle est en cours d’exécution pour être affichée en réponse d’une requête pertinente.
- Le RANKING : Cette phase correspond au moment où la réponse de votre recherche va être envoyée. Elle sera classée par ordre de pertinence selon des choix, filtres et critères.

Elasticsearch se présente comme un outil de gestion de base de données qui permet d’une part de stocker des données et d’autre de récupérer ses données au moyen de requêtes . Il présente les avantages suivants :
- Les recherches peuvent être basées sur du texte et les requêtes peuvent être très poussées.
- La possibilité d’organiser les résultats de recherche par pertinence (score).
- Les données sont stockées de manière non structurée: Plusieurs objets de structure différente peuvent être sauvegardés au sein d’un même index (équivalent d’une table dans une base relationnelle).
- la communication se fait via une api REST.
- Elasticsearch peut fonctionner en mode distribué: plusieurs instances peuvent communiquer entre elles par le réseau afin d’optimiser le temps de réponse.
Installation et démarrage d’elasticsearch
Prérequis: JRE doit être installé et la variable JAVA_HOME configurée.
1 – Télécharger elasticsearch. Nous allons récupérer la version zip car étant sous windows.
2- Décompresser l’archive sur votre système.
En ligne de commande lancer elasticsearch depuis le répertoire elasticsearch\bin
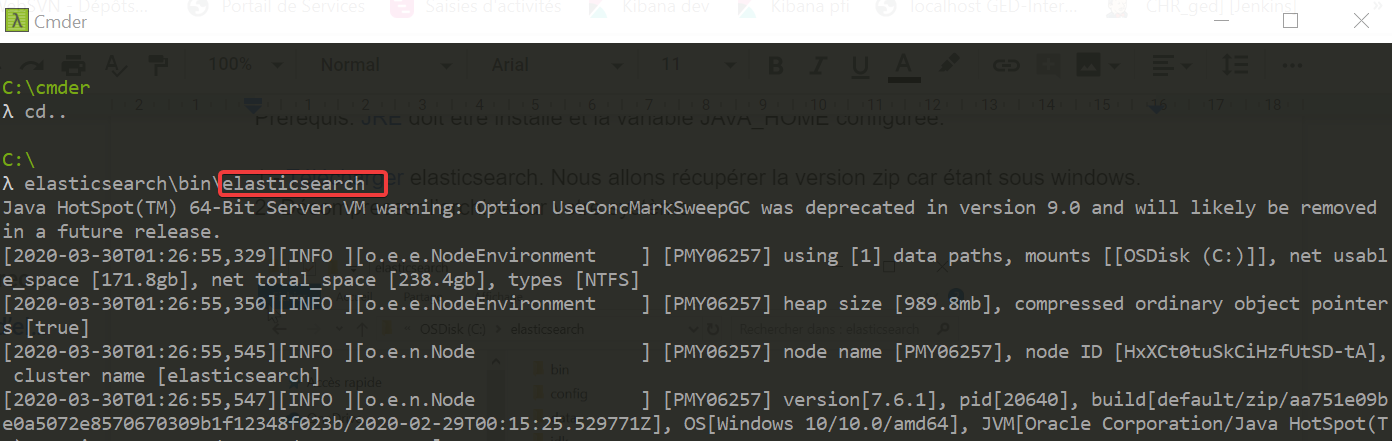
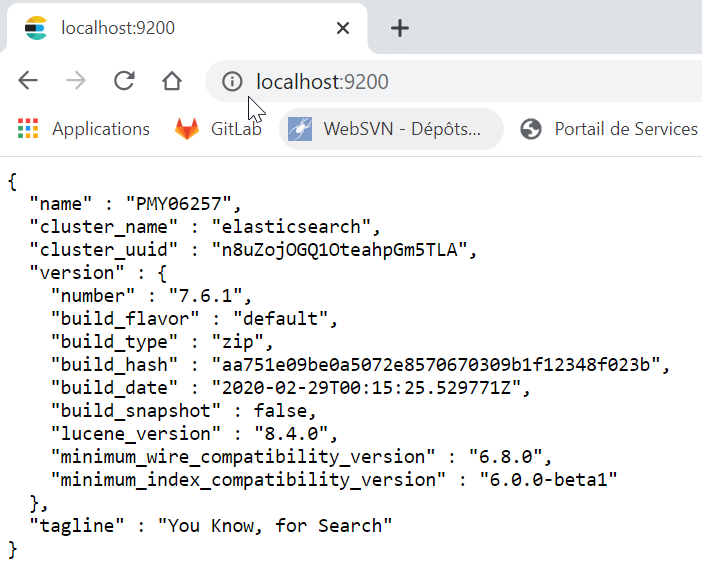
le serveur démarre et écoute le port 9200 par défaut.

sur le navigateur on peut l’atteindre ne tapant localhost:9200
kibana
Comme introduit dans cet article, kibana est un outil graphique conçue pour manipuler les données stockées dans elasticsearch. Kibana peut également être branché sur n’importe quel cluster elasticsearch.
Installation
- Télécharger ici la version la plus récente qui correspond au système d’exploitation.
Application
Nous travaillerons sur une base de données stockant des documents douanes (factures, ou documents annexes…).
A cet effet, nous allons créer notre index (base) dans elasticsearch “ged” puis alimenterons celle-ci avec des factures de type “_doc”.
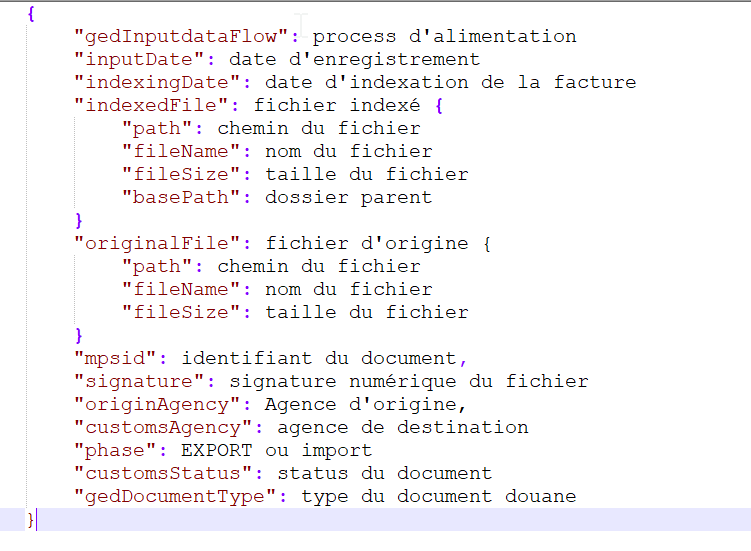
Structure d’un objet de type “_doc” :
- Démarrer elasticsearch comme vu précédemment.
- Lancer kibana : décompresser le binaire télécharger puis lancer le binaire kibana :
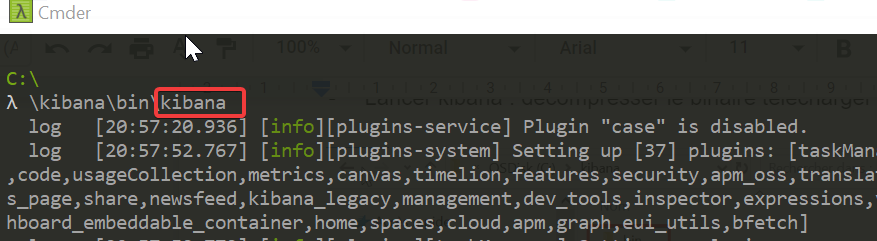
kibana, écoute le port 5601 par défaut.

1 Lancer kibana dans votre navigateur : http://localhost:5601
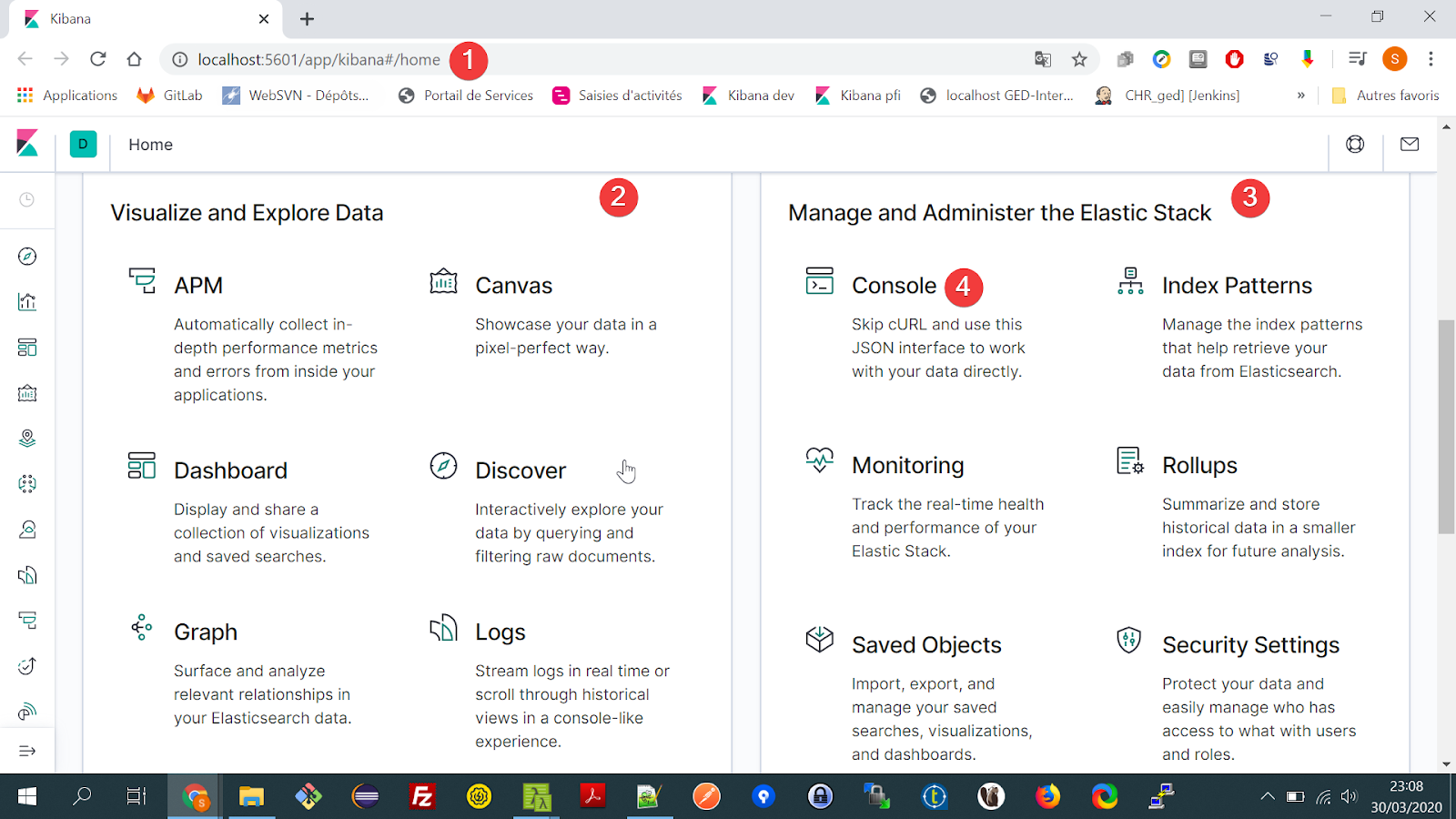
2 Panel outils de visualisation et manipulation des données
3 Panel gestion et d’administration d’elasticsearch
4 Interface JSON permettant d’écrire des requêtes vers elasticsearch.
Création de l’index ged et ajout de documents : Accédons à l’interface JSON (4) .
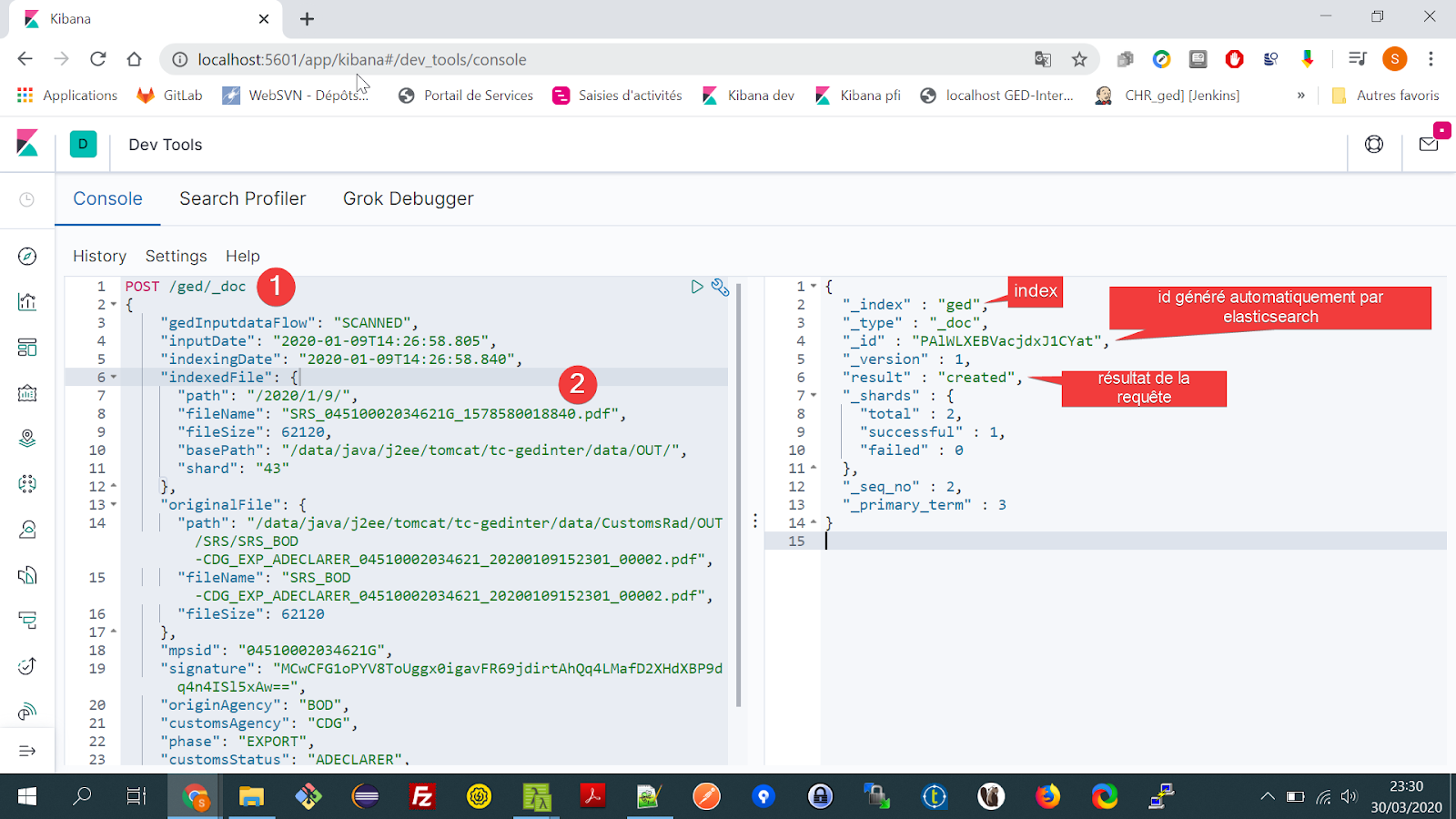
1 Création de l’index ged des objets de types _doc*
2 document à créer.
Nous allons ainsi répéter la création de documents afin d’avoir plus de données dans l’index ged .
Exploration de données
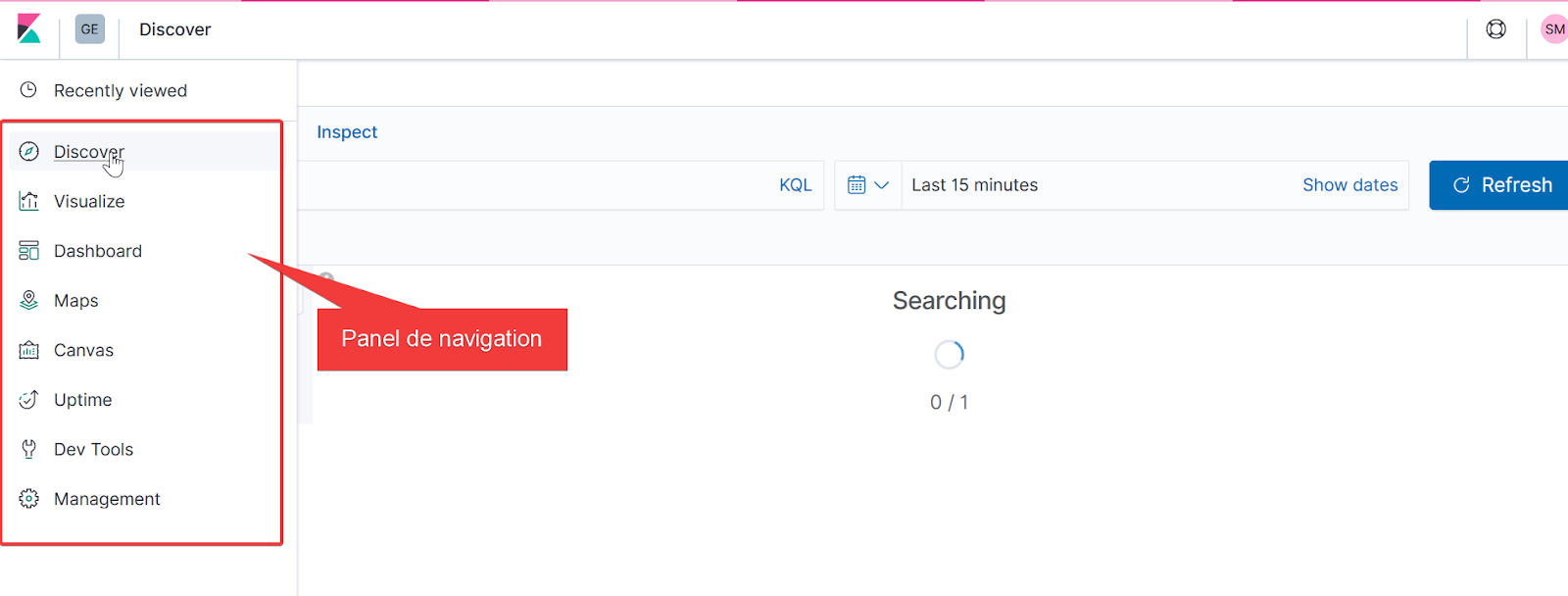
Onglet : Discover
1 Exemple de barre de recherche full text : affiche les document archivé
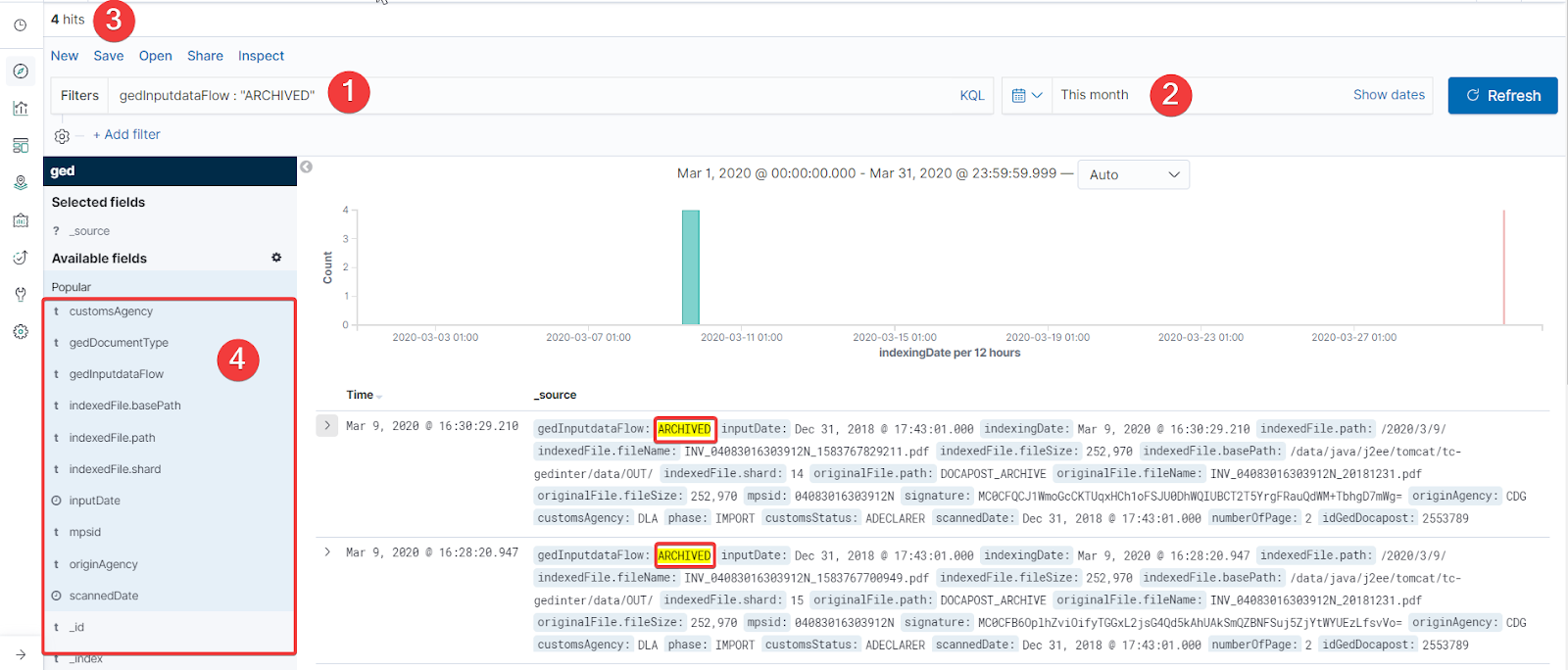
2 filtre par calendrier : affiche ici uniquement les résultat du mois courant.
3 nombre de résultats filtrés.
4 panel des attributs d’objet: permet de n’afficher que les propriétés d’objet souhaités
L’onglet Visualize: Permet de créer des visualisations de nos données sous forme de graphe en ligne , tableau,histogramme…
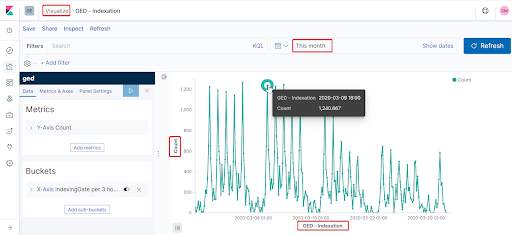
Nous pouvons par exemple dans notre cas, créer un graphe représentatif du nombre de document indexés dans elasticsearch par intervalle de temps (toutes les 3 heures dans l’exemple ci-bas) sur le mois en cours.
Nous pouvons également visualiser sous forme de table, le nombre de documents indexés par agence pour le type CustomRad.
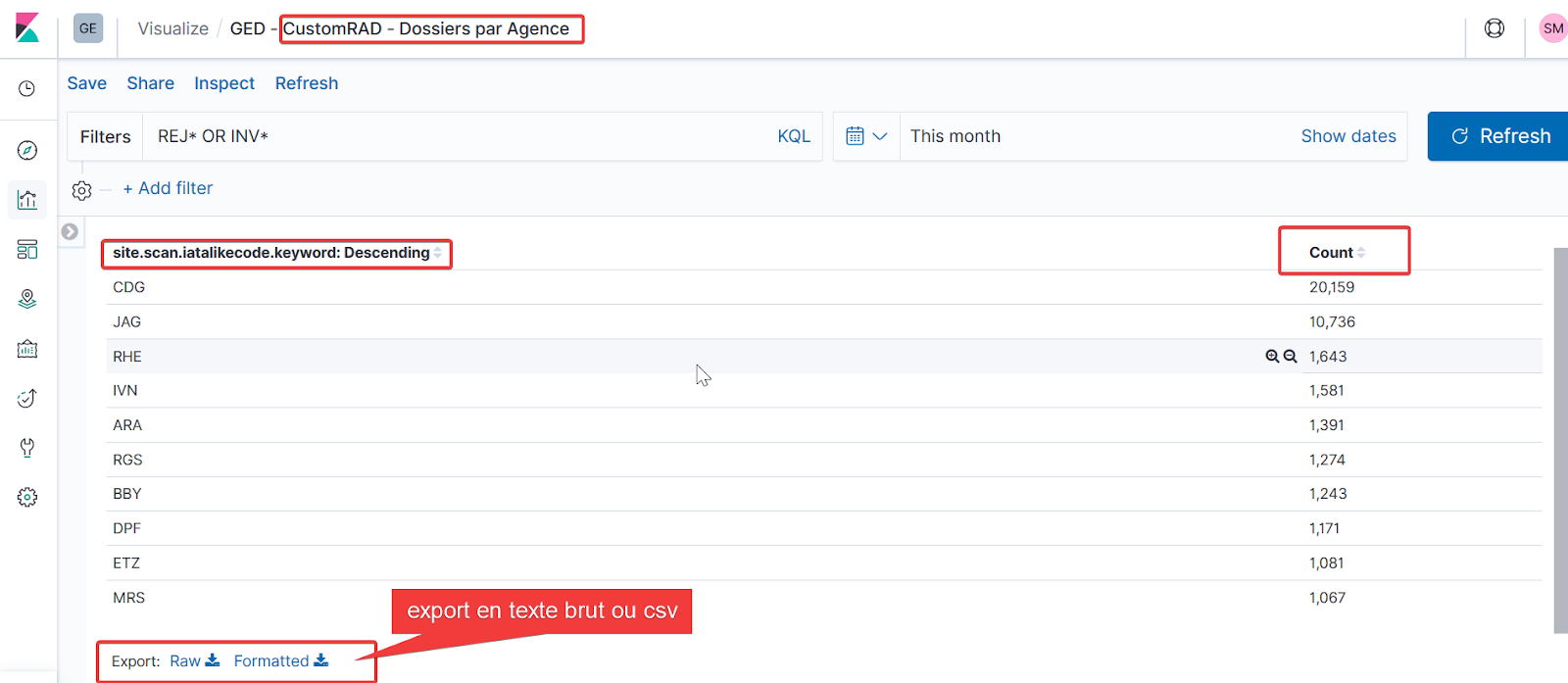
Analyse de logs
Les logs sont des fichiers journaux générés par le serveur et qui permettent d’enregistrer un trace de chaque appel au serveur.
En réalité, l’utilisation de kibana de manière optimale pour scruter les logs se fait via l’association de l’outil Filebeat et de trois solutions open source de la suite ELK: Elasticsearch + Logstash + Kibana.
Nous associerons également .
Filebeat : Permet le transfert des fichiers de log vers un point défini.
LOGSTASH : extrait les données des fichiers de log, les filtres et les indexe dans Elasticsearch.

Configuration et installation :
FILEBEAT
- https://www.elastic.co/downloads/past-releases/filebeat-5-2-1
- https://www.elastic.co/guide/en/beats/filebeat/5.2/filebeat-installation.html
Le fichier de configuration de filebeat est le filebeat.yml les variables
${FLOWER_LOG_FOLDER} et ${TOMCAT_HOME} sont à définir.
Des prospectors sont définis dans le fichier filebeat.yml. Ils correspondent chacun à une configuration pour injecter des fichiers de logs :
- Nom et chemin des fichiers
- Eventuellement, gestion des multi-lignes (exemple : stacktrace d’une exception)
- Champs à ajouter pour chaque ligne
Ecriture vers logstash :
output.logstash: hosts: ["localhost:5044"]
Plus de détails ici : https://www.elastic.co/guide/en/beats/filebeat/current/how-filebeat-works.html
LOGSTASH
Pour envoyer les logs vers elasticsearch:
input { stdin { } }
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
Démarrage de logstash: bin/logstash -f nomFichierConfiguration.conf
Plus de détails :
- https://www.elastic.co/guide/en/logstash/current/configuration.html
- https://www.elastic.co/downloads/past-releases/logstash-5-2-1
- https://www.elastic.co/guide/en/logstash/5.2/installing-logstash.html
- https://www.elastic.co/guide/en/logstash/current/configuration.html
Test de la configuration :
- Lancer Elasticsearch
- Démarrer Logstash : ouvrir une invite de commande dans le répertoire ${LOGSTASH_HOME}/bin et entrer la commande suivante : logstash -f nomFichierConfiguration.conf –config.reload.automatic
- Attendre le démarrage et vérifier qu’il n’y a pas d’erreur liées à la configuration
- Démarrer Filebeat : Ouvrir les services Windows et démarrer le service.
- Ouvrir les logs Filebeat (${FILEBEAT_HOME}/logs/filebeat) et vérifier que des fichiers logs sont bien présents.
Visualisation des logs dans elasticsearch:
Dans la continuité de notre exemple, un événement devrait ressembler à la capture suivante:
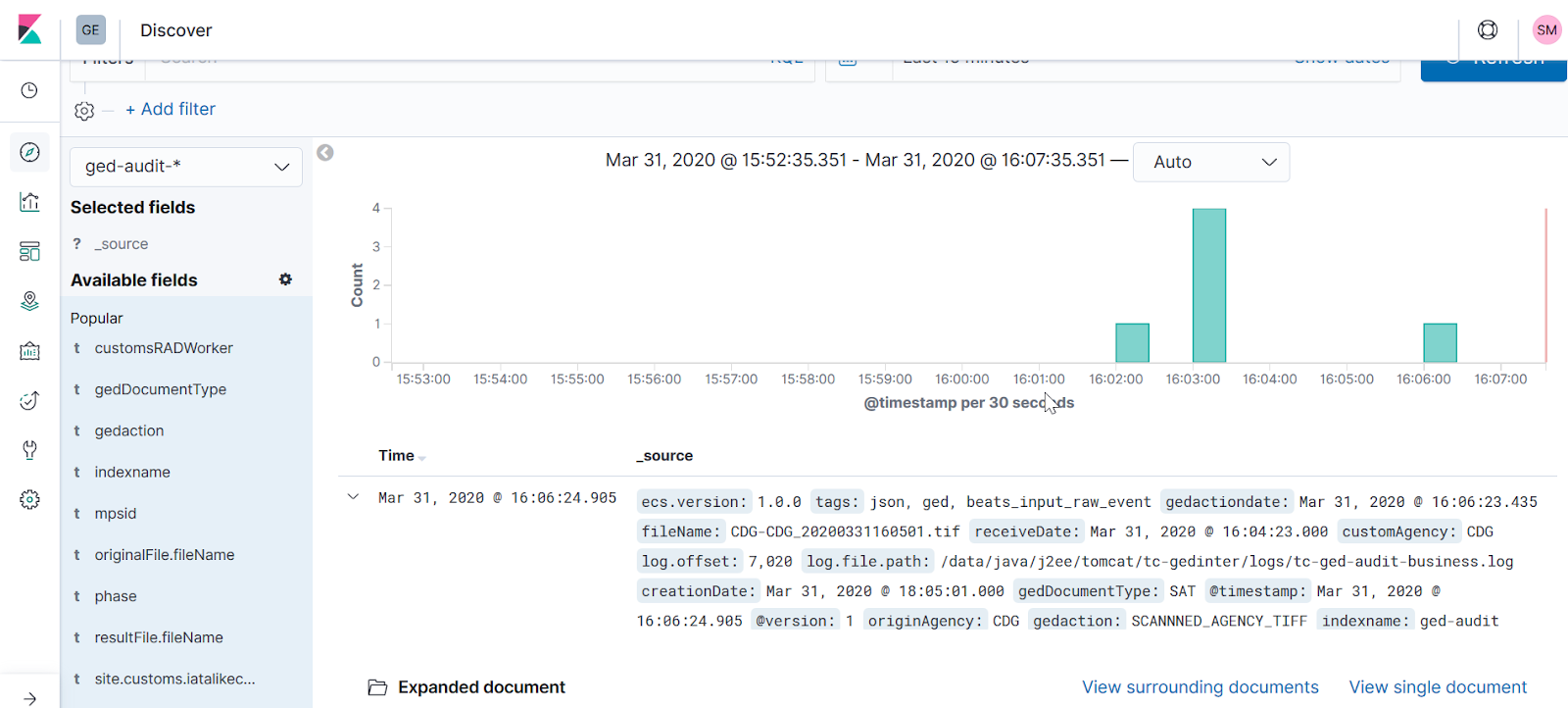
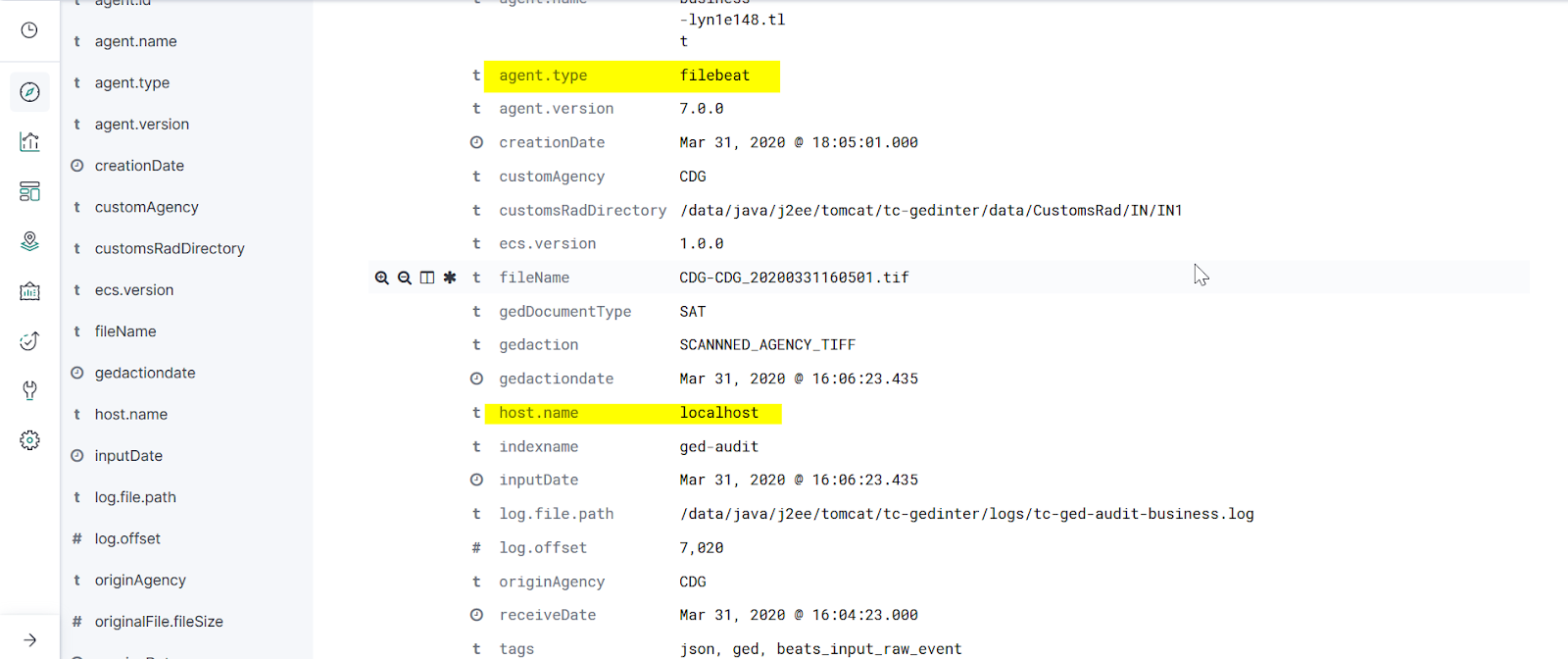
Cet article a été l’occasion de voir un aperçu assez rapide de kibana; II s’agit là d’un outil très simple et en même tant extrêmement puissant pour l’exploration de données. kibana rend désormais elasticsearch quasiment incontournable pour les équipes d’analyse et de décision. Toutefois, notez bien qu’il est recommandé de ne pas utiliser elasticsearch comme base de données principale et privilégier les bases traditionnelles (relationnelles…) pour la cohérence de données. En pratique, les données sont transférées dans elasticsearch depuis une base relationnelle, puis visualiser via kibana par des utilisateurs. Toutefois, un bon compromis devra toujours être fait entre nombres de requêtes depuis kibana par les d’utilisateurs et la capacité du cluster, afin d’éviter de mettre à mal elasticsearch.