L’évolution technologique des SI tend à les complexifier. À ce titre, le tracing de l’activité via les logs revêt une importance plus que jamais déterminante. Il convient de les centraliser et d’en rationaliser la gestion. Faisons le point sur le sujet.
En raison de la complexité du suivi fonctionnel des applications, des infrastructures qui deviennent de plus en plus distribuées, et de la démultiplication des interactions entre les différents composants. La centralisation des logs devient primordiale. Elle permet de :
- veiller au fonctionnement d’une application ou d’un système ;aciliter le diagnostic d’un comportement anormal ;
- la journalisation de l’application ;
- comprendre le fonctionnement d’une application ;
- le profilage des performances ;
- faciliter le monitoring et la supervision.
Qu’est ce qu’un log ?
Pour comprendre l’utilité de la centralisation des logs, revenons d’abord à ce qu’est un log.
Un système doit être en mesure de tracer toutes ses activités pour faciliter d’une part le suivi de son fonctionnement, et d’ autre part, faciliter l’analyse des bugs qui peuvent survenir. Ces traces sont appelées des logs. Elles sont au cœur du concept d’historique des événements ou d’historisation et prennent la forme d’un fichier qui contient cet historique.
Les différents types de logs
Il existe différents types de logs permettant de garantir la sécurité et le bon fonctionnement des applications d’un système d’information.
Parmi les principaux logs utilisés (liste non exhaustive) : les logs applicatifs, les logs Systèmes, les logs de base de données ou de trafic http(s).
La centralisation des logs
La centralisation des logs est une étape très importante dans le cycle de vie d’un système informatique. Il implique plusieurs étapes :
- La production de logs définis selon les objectifs de la centralisation.
- Le regroupement des logs dans une plateforme commune.
- L’analyse et le filtrage des métriques pour répondre aux différents besoins de monitoring.
- La mise en place d’outils graphiques pour faciliter l’exploitation.
Outils de centralisation et d’exploitation des logs
Il y a de nombreux outils qui permettent la mise en place de la centralisation, l’indexation, le stockage ou le traitement (sécurité, graphique…) des logs. Ils sont essentiels à la sécurité d’un système d’information et doivent faire partie de la réflexion dès les premiers temps de son déploiement ou de sa mise à l’échelle.
Exemples d’outils parmi les plus utilisés :
Rsyslog
Rsyslog est un programme open source comprenantun serveur Syslog, qui permet la centralisation de l’ensemble des logs de divers serveurs, switchs, ou firewalls.
Il se base sur le protocole Syslog (System Logging Protocol) qui sert à l’envoi et la réception des fichiers du journal Système ou des messages liés à des événements. Il permet de réaliser des requêtes pour en extraire des informations et générer des tableaux de bord.
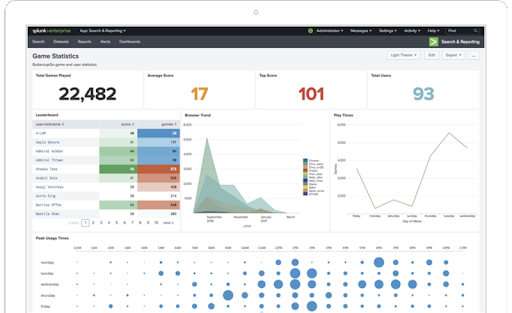
Splunk
Un logiciel d’indexation permettant de rechercher au sein d’une grande quantité de données logs pour en extraire les informations pertinentes.
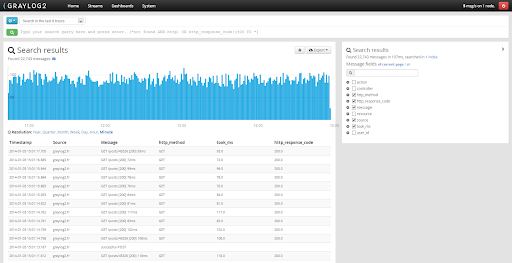
Graylog
Une des solutions open source de gestion de logs. Les données provenant de plusieurs serveurs sont enregistrées dans une base de données Elasticsearch, qui permet l’indexation et la recherche des données, Il comporte également une interface web autorisant la gestion et l’analyse des logs.
ELK
Une solution open source qui combine trois outils puissants et complémentaires : Elasticsearch, qui comme Splunk est un logiciel d’indexation, Logstash pour collecter et stocker les données, et Kibana dont le rôle est d’organiser visuellement les données.
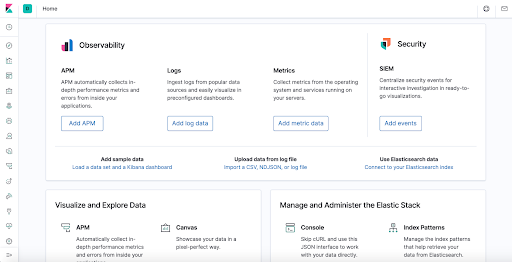
Exemple d’outils de centralisation et d’exploitation des logs : ELK

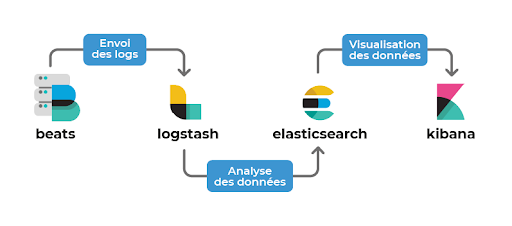
Comme décrit ci-dessus, ELK comprend les trois composants principaux Elasticsearch, Logstash et Kibana.
Beats a ensuite été ajouté pour former la stack ELK.
Beats : est installé sur les machines à monitorer en “agent” pour remonter les fichiers de journalisation à Logstash ou à Elasticsearch.
Logstash : permet le traitement des données Elastic Stack.
Elasticsearch : le moteur de recherche RESTful distribué qui stocke toutes les données recueillies.
Kibana : le plug-in open source lié à Elasticsearch pour la visualisation et la création des tableaux de bord dédiés aux index présentés dans la recherche Elasticsearch.
Installation d’ELK
Pour faciliter l’installation est la mise en place nous allons utiliser Docker et Ubuntu :
- Crée un dossier Kibana Docker
- Dans ce dossier, nous allons créer un fichier nommé kibana.yml qui contiendra :
server.name:kibana
server.host: »0″
elasticsearch.hosts:[« http://ADRESSE_IP_ES:9200 »]
3. Et pour finir lancer la commande :
docker run -d –namekibana -p 5601:5601 –volume $PWD/kibana.yml:/usr/share/kibana/config/kibana.yml docker.elastic.co/kibana/kibana:7.10.1
4. Télécharger et installer la clé publique de dépôt officie :
wget -qO – https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudoapt-key add –
5. Installer le paquet apt-transport-https :
sudo apt-get installapt-transport-https
6. Ajouter elastic-7.x.list dans /etc/apt/sources.list.d/ :
echo « deb https://artifacts.elastic.co/packages/7.x/apt stable main » | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
7. Et enfin lancer l’installation du service :
sudo apt-get update &&sudo apt-get installkibana
8. Lancement du service :
sudo apt-get update &&sudo apt-get installkibana
À noter : on peut aussi faire en sorte que le service se lance au démarrage du système :
systemctl enable kibana
Exploration des tableaux de bord Kibana
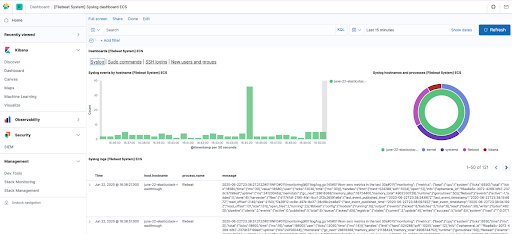
Kibana est principalement composé de six onglets :
– Discover (Découvrir) : permet de rechercher et filtrer les données indexées récoltées par elasticSearch, d’obtenir des informations sur la structure des champs et d’afficher les résultats dans une visualisation. Il est également possible de personnaliser et d’enregistrer les recherches et de les placer sur un tableau de bord.
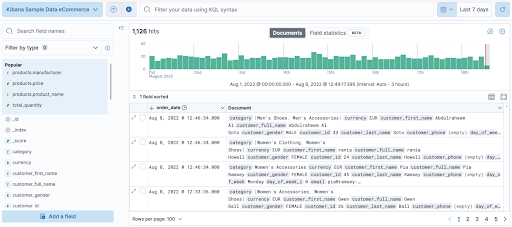
– Dashboard (Tableau de bord) : permet de visualiser les données récoltées en une collection de panneaux. On se concentre uniquement sur les données « métier » ou « serveur » selon le but du Dashboard.
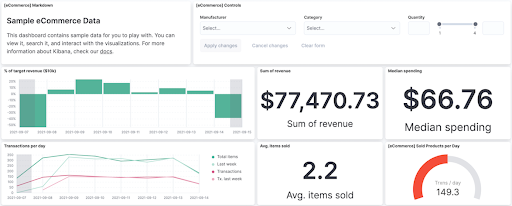
– Canvas (Toile) : un outil de visualisation et de présentation de données qui permet d’extraire ces dernières directement depuis Elasticsearch et de créer et/ou personnaliser visuellement son espace de travail : arrière-plans, bordures, couleurs, polices, etc.
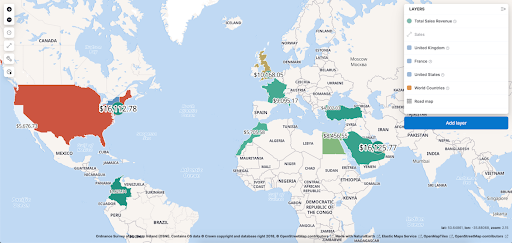
–Maps (niveaux de zoom) : Permet l’analyse des données géographiques en temps réel, à l’échelle, et de façon inédite.
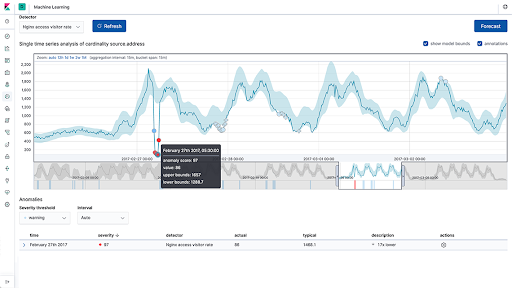
-Machine Learning : permet l’extraction des données Elasticsearch, de simplifier la création de tâches de Machine Learning (comme détecter un ralentissement des temps de réponse directement dans l’application APM, ou encore de découvrir un comportement inattendu via l’application SIEM). Cette solution détecte également les anomalies dans les données par la modélisation de séries temporelles.
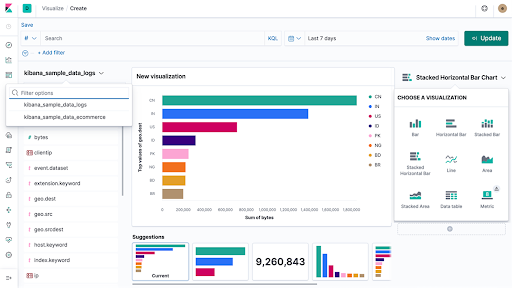
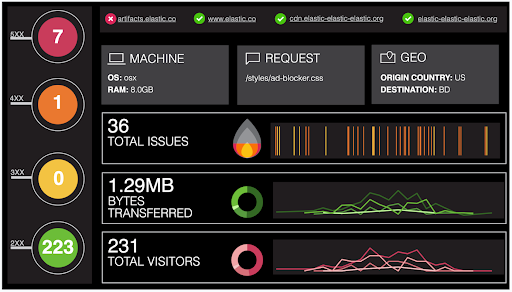
– Visualize (Visualiseur de données pour les fichiers) : visualisation est un outil de présentation des données d’Elasticsearch.