
Vous utilisez Kubernetes pour gérer vos applications conteneurisées, mais vous n’êtes pas sûr de l’optimiser au mieux ?
Ne vous inquiétez pas, cet article est fait pour vous ! Nous allons explorer les meilleures pratiques pour optimiser votre déploiement Kubernetes. Mais avant de plonger dans le vif du sujet, nous commencerons par une introduction à Kubernetes, ses concepts de base et pourquoi vous devriez l’utiliser.
Aucune connaissance approfondie de Kubernetes n’est requise, mais il est recommandé de connaître les bases de la gestion de conteneurs.
1. Introduction à Kubernetes
1.1 Qu’est-ce que Kubernetes ?
Kubernetes est une plateforme open-source permettant d’automatiser le déploiement, la mise à l’échelle et la gestion des applications conteneurisées. Google a rendu open-source le projet Kubernetes en 2014 et est maintenant maintenu par la Cloud Native Computing Foundation (CNCF).
Kubernetes fournit un environnement de gestion focalisé sur le conteneur (container-centric). Les conteneurs sont des unités logicielles portables qui contiennent tout ce dont une application a besoin pour s’exécuter, y compris le code, les dépendances et les fichiers de configuration. Kubernetes fournit un cadre pour orchestrer ces conteneurs, ce qui signifie qu’il gère leur déploiement, leur mise à l’échelle et leur surveillance.
1.2 Pourquoi utiliser Kubernetes ?
Les principales raisons pour lesquelles les entreprises utilisent Kubernetes :
-
- Gestion efficace des conteneurs : Kubernetes facilite la gestion des conteneurs, qui permettent d’isoler les applications et de les déployer de manière cohérente dans différents environnements.
- Automatisation du déploiement : Kubernetes permet d’automatiser le déploiement d’applications, ce qui réduit le risque d’erreurs et accélère la mise en production.
- Scalabilité : Kubernetes permet de mettre à l’échelle facilement les applications en fonction de la charge de travail des utilisateurs (workloads), en ajoutant ou en supprimant des conteneurs en temps réel.
- Haute disponibilité : Kubernetes offre des fonctionnalités avancées pour garantir la haute disponibilité des applications en cas de défaillance, notamment la réplication automatique des conteneurs.
- Gestion des mises à jour : Kubernetes facilite la gestion des mises à jour et des versions d’application en permettant de les déployer de manière progressive sans interruption de service et en veillant à ce que les nouvelles versions soient testées avant d’être déployées en production.
- Gestion des ressources : Kubernetes permet de gérer efficacement les ressources (CPU, mémoire, etc.) pour optimiser les performances des applications et réduire les coûts d’infrastructure.
- Sécurité : Kubernetes offre des fonctionnalités de sécurité avancées pour les conteneurs, notamment la segmentation de réseau, la gestion des secrets et des certificats.
- Portabilité : Kubernetes permet de déployer des applications sur différents environnements (cloud public, cloud privé, sur site) sans avoir à modifier le code.
1.3 Concepts de base de Kubernetes
Un cluster Kubernetes se compose d’un ensemble de machines (Worker Nodes), qui exécutent des applications conteneurisées et qui sont gérées par le plan de contrôle (Control Plane / Master Node). Le schéma suivant décrit les différents composants nécessaires pour obtenir un cluster Kubernetes :
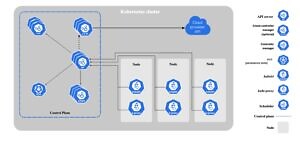
-
- Node : les nœuds Kubernetes sont les machines physiques ou virtuelles sur lesquelles les pods sont déployés et exécutés. Les nœuds fournissent les ressources nécessaires aux pods, telles que la mémoire, le CPU et le stockage.
- kube-apiserver : c’est le point d’entrée de l’API Kubernetes. Tous les autres composants communiquent avec l’API via le kube-apiserver. Il s’agit d’un composant crucial de la plateforme, car il gère l’authentification, l’autorisation et la validation des demandes API.
- etcd : il s’agit d’une base de données distribuée utilisée pour stocker l’état de la plateforme et les informations relatives à la configuration telles que les informations sur les nœuds, les pods déployés et les services créés.
- kube-scheduler : ce composant est responsable de la planification des pods sur les différents nœuds du cluster. Il examine les besoins en ressources des pods et décide sur quel nœud les faire tourner en fonction des ressources disponibles et des contraintes spécifiées.
- kube-controller-manager : Il comprend plusieurs contrôleurs, tels que le contrôleur de réplication et le contrôleur de service. Le contrôleur de réplication veille à ce que le nombre de répliques de chaque pod soit toujours conforme aux spécifications, tandis que le contrôleur de service s’assure que les services sont accessibles aux utilisateurs.
Le diagramme suivant montre les principaux objets Kubernetes disposés dans un Worker Node :
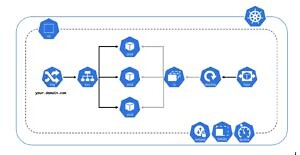
Nous mettrons l’accent sur les objets essentiels utilisés pour déployer et gérer des applications conteneurisées:
-
- Pod : La plus petite unité déployable dans Kubernetes. Il contient un ou plusieurs conteneurs et partage le même espace de réseau et de stockage. Les pods sont créés pour exécuter des tâches spécifiques et peuvent être déployés et gérés indépendamment les uns des autres.
- Service (svc) : Fournit une interface stable pour accéder aux pods. Les services permettent de regrouper des pods et de leur attribuer une adresse IP et un nom DNS pour les rendre accessibles à d’autres composants de l’application.
- ReplicaSet (rs) : les réplicas sont des copies de pods créées pour garantir que l’application est disponible en permanence, même en cas de panne d’un ou plusieurs pods. Les réplicas sont créées par les ReplicaSets qui veillent à ce que le nombre de réplicas corresponde toujours à la spécification.
- Deployment (deploy) : Permet de définir la stratégie de mise à jour, de contrôler le nombre de répliques de pods en cours d’exécution et de mettre à jour les pods de manière progressive et automatisée.
- Namespace (ns) : Permet de diviser un cluster Kubernetes en plusieurs environnements logiques isolés, organiser et gérer les ressources Kubernetes de manière logique et isolée et également fournir un environnement multi-utilisateur dans lequel plusieurs équipes peuvent travailler indépendamment les unes des autres.
2. Astuces et meilleures pratiques
2.1 Bien définir les quotas et limites de ressources pour les pods
Chaque pod a besoin d’une certaine quantité de ressources pour fonctionner correctement, notamment de la CPU, de la mémoire, du stockage et de la bande passante réseau.
Définir les quotas (ResourceQuota) et les limites de ressources permet de garantir que les pods ont suffisamment de ressources pour fonctionner, tout en évitant que les ressources ne soient gaspillées ou que le cluster ne soit surchargé.
On peut définir une ResourceQuota au niveau namespace comme suit :
Dans cet exemple, nous avons limité le nombre total de pods à 10, les demandes de CPU à 2 unités et la mémoire demandée à 4 gigaoctets. Nous avons également mis les limites de CPU à 4 unités et de mémoire à 8 gigaoctets. Ainsi, avec cette configuration, Kubernetes va s’assurer que les pods créés dans le namespace associé à cette ResourceQuota ne dépassent pas les limites définies pour les ressources spécifiées.
On peut également définir des limites de ressources au niveau pod comme suit :
2.2 Coupler les pods avec les objets Deployments / ReplicaSets
Pour garantir une haute disponibilité de vos applications dans Kubernetes, il est fortement recommandé de ne pas utiliser de pods « nus » qui ne sont pas liés à un ReplicaSet ou à un Deployment. Les pods nus ne seront pas ré-ordonnancés en cas de panne de nœud (Node), ce qui peut entraîner une interruption de service.
Pour automatiser la gestion des pods et des répliques, mettre à l’échelle facilement et garantir une haute disponibilité de votre application, il est préférable d’utiliser des objets Kubernetes tels que les Deployments (qui créent au même temps des ReplicaSets) pour garantir que le nombre de pods souhaité est toujours disponible.
Les Deployments facilitent aussi l’utilisation de stratégies de déploiement progressives (telles que Canary ou Blue-Green) ainsi on peut minimiser les interruptions de service lors des mises à jour d’application.
Dans cet exemple, nous avons créé un Deployment appelé « my-app » qui utilise un ReplicaSet pour gérer les répliques des pods. Le Deployment spécifie que nous voulons 3 répliques de notre pod. Le champ « selector » spécifie comment le ReplicaSet doit identifier les pods associés avec le label « app: my-app ».
2.3 Organiser les objets avec les labels et les annotations
Dans Kubernetes, l’organisation des objets est cruciale pour leur gestion efficace. Les labels et les annotations sont des moyens de regrouper et de catégoriser les objets selon leur rôle, environnement, service ou propriétaire. Cela facilite la recherche, la surveillance et la gestion des objets dans les environnements complexes.
Les labels sont utilisés pour filtrer et sélectionner des objets, tandis que les annotations sont utilisées pour fournir des informations supplémentaires sur les objets.çàp
Supposons que vous avez plusieurs services déployés dans votre cluster Kubernetes, tels qu’un service Web, une base de données et un service de cache. Vous pouvez utiliser des labels pour organiser ces services en groupes logiques, par exemple en leur attribuant des labels (kubectl label) tels que « type=frontend » pour le service Web, « type=database » pour la base de données et « type=cache » pour le service de cache. Ainsi, vous pouvez facilement sélectionner par exemple les pods appartenant au service Web par la commande :
kubectl get pods -l type=frontend
Vous pouvez également utiliser des annotations pour ajouter des informations supplémentaires aux objets Kubernetes. Par exemple, l’annotation « appVersion=v1.2.3 » au niveau de l’objet Deployment pour indiquer la version de l’application déployée (kubectl annotate). Ces informations peuvent être utiles pour suivre les versions des applications, pour déployer des mises à jour de manière contrôlée et faciliter le débogage en cas de problèmes.
2.4 Utiliser une stratégie de mise à l’échelle automatique
L’un des avantages les plus importants de Kubernetes est sa capacité à mettre à l’échelle automatiquement les applications en fonction de la demande. Cela permet de maintenir une performance constante de l’application tout en minimisant les coûts d’infrastructure. Il existe deux types de stratégies de mise à l’échelle automatique dans Kubernetes : la mise à l’échelle horizontale et la mise à l’échelle verticale.
La mise à l’échelle horizontale (Horizontal Pod Autoscaler) permet d’augmenter ou de diminuer le nombre de pods en fonction de la demande. Par exemple, si le nombre de requêtes HTTP augmente, le nombre de pods augmentera automatiquement pour répondre à la demande. Il est possible de définir des limites supérieures et inférieures pour la mise à l’échelle horizontale.
La mise à l’échelle verticale (Vertical Pod Autoscaler) permet d’ajuster automatiquement les limites de ressources allouées à un pod en fonction de la demande. Par exemple, si un pod a besoin de plus de mémoire pour traiter une demande spécifique, la mise à l’échelle verticale augmentera automatiquement la quantité de mémoire allouée à ce pod.
Il est recommandé d’utiliser une combinaison des deux stratégies de mise à l’échelle automatique pour maximiser la performance et minimiser les coûts. Voici un exemple de fichier de configuration YAML pour la mise à l’échelle horizontale :
Ce fichier de configuration définit une mise à l’échelle horizontale pour le déploiement « my-app », avec un minimum de 1 pod et un maximum de 10 pods. La mise à l’échelle horizontale sera basée sur l’utilisation de la CPU, avec une utilisation cible de 50%.
2.5 Utiliser des images légères et optimisés
L’utilisation d’images légères et optimisées pour vos conteneurs peut avoir un impact significatif sur la performance et l’efficacité de votre déploiement Kubernetes. En effet, les images légères nécessitent moins de ressources pour être exécutées et peuvent donc contribuer à réduire la consommation de CPU, de mémoire et d’espace de stockage. De plus, les images optimisées peuvent réduire les temps de téléchargement et de démarrage des conteneurs, ce qui peut améliorer la vitesse de déploiement de vos applications.
Pour optimiser vos images, vous pouvez suivre quelques bonnes pratiques,
telles que :
-
- Évitez d’inclure des fichiers inutiles dans vos images, tels que des fichiers de log ou des fichiers temporaires.
- Utilisez des images de base officielles, telles que celles fournies par les éditeurs de logiciels, qui sont souvent optimisées pour les conteneurs.
- Évitez d’utiliser des images obsolètes ou de versions antérieures, car elles peuvent contenir des vulnérabilités de sécurité ou des bugs connus.
- Utilisez des outils de création d’images, tels que Docker Build, pour optimiser et minimiser la taille de vos images.
- Mettez à jour régulièrement vos images pour inclure les dernières mises à jour de sécurité et les correctifs de bugs.
Par exemple, si vous utilisez une application Node.js, vous pouvez utiliser une image de base officielle, telle que node:alpine, qui est optimisée pour les conteneurs et ne contient que les packages nécessaires pour exécuter Node.js. De même, si vous utilisez une base de données, vous pouvez utiliser une image officielle, telle que mysql:5.7, qui est optimisée pour les conteneurs et fournit des options de configuration par défaut pour une utilisation en production.
2.6 Assigner les pods aux nœuds on utilisant les Pod/Node Affinity et Taints
Lors du déploiement de vos pods sur un cluster Kubernetes, vous pouvez vouloir spécifier sur quel nœud chaque pod doit être planifié et exécuté, en fonction de certains critères tels que les ressources disponibles, la localisation du nœud ou tout autre critère spécifique à votre application.
Les Pod/Node Affinity vous permettent de spécifier des règles pour que les pods soient planifiés sur des nœuds spécifiques en fonction de leur labels. Par exemple, vous pouvez définir une affinité pour planifier un pod sur un nœud ayant une certaine quantité de mémoire ou un nœud dans une région spécifique. Voici un exemple de configuration YAML pour spécifier une Pod Affinity qui demande un nœud avec un label spécifique:
Les marques de nœud (Taints) vous permettent de spécifier des restrictions pour empêcher les pods d’être planifiés sur certains nœuds, sauf s’ils ont une tolérance spécifique pour ces restrictions. Cela peut être utilisé pour exclure certains nœuds de l’utilisation, ou pour réserver certains nœuds pour des tâches spécifiques.
Par exemple, vous pouvez empêcher les pods d’être planifiés sur un nœud qui a une capacité limitée en mémoire. Voici un exemple de configuration YAML pour ajouter un Taint à un nœud pour empêcher la planification de nouveaux pods s’ ils ont une consommation mémoire élevée :
2.7 Configurer les Liveness, Readiness et Startup Probes
Il est important de s’assurer que les applications déployées sur Kubernetes fonctionnent correctement en permanence. Pour cela, Kubernetes propose les Liveness Probes, les Readiness Probes et les Startup Probes:
-
- La Liveness Probe vérifie si une application est en cours d’exécution correctement. Si le check échoue, le conteneur sera arrêté et redémarré automatiquement.
- La Readiness Probe vérifie si l’application est prête à recevoir du trafic réseau. Si la Readiness Probe échoue, Kubernetes considère l’application comme non disponible, ainsi, l’application ne va pas recevoir du trafic réseau via les services Kubernetes (toutefois le conteneur n’est pas arrêté).
- La Startup Probe vérifie si l’application a correctement démarrée et a terminé son initialisation. Si la Startup Probe échoue, Kubernetes marque le pod comme en échec et redémarre l’application. La Startup Probe est généralement utilisée pour les conteneurs qui prennent beaucoup de temps à démarrer.
Voici un exemple de configuration YAML pour définir les probes pour un conteneur :
Dans cet exemple, la Liveness Probe vérifie la santé du conteneur en interrogeant l’URL « /healthz » toutes les 10 secondes, après une pause initiale de 15 secondes. La Readiness Probe vérifie la disponibilité du conteneur en interrogeant l’URL « /ready » toutes les 10 secondes, après une pause initiale de 5 secondes.
2.8 Utiliser des outils de surveillance et de gestion de logs
La surveillance des applications Kubernetes est essentielle pour maintenir leur disponibilité et leur performance. Il existe de nombreux outils open-source de surveillance des applications Kubernetes, tels que :
Prometheus est un outil de surveillance qui collecte les métriques des applications Kubernetes, les stocke dans une base de données et permet également d’alerter les utilisateurs lorsque les seuils de performance sont atteints ou dépassés.
Grafana est un outil de visualisation de données qui peut être utilisé avec Prometheus pour créer des tableaux de bord et des graphiques personnalisés pour surveiller les performances de votre application Kubernetes.
L’ELK Stack est un autre outil populaire qui peut être utilisé pour surveiller les journaux d’application. Il se compose de trois composants principaux : Elasticsearch, Logstash et Kibana. Logstash est utilisé pour collecter et traiter les journaux, Elasticsearch pour stocker les données et Kibana pour visualiser les données stockées.
3. Conclusion
Même si Kubernetes est un outil puissant pour la gestion des applications conteneurisées, il peut être difficile à optimiser. L’un des principaux défis est la complexité de la plateforme et la multitude d’options disponibles pour la configuration. Les développeurs et les administrateurs doivent comprendre les besoins de leurs applications et choisir les paramètres qui conviennent le mieux à leur cas d’utilisation.
La sécurité est également un défi important. Kubernetes est une plateforme complexe avec de nombreux composants, et il est important de s’assurer que ces composants sont configurés de manière sécurisée.
L’optimisation de Kubernetes peut être un défi. Cependant, relever ce défi présente de nombreux avantages pour votre déploiement. Tout d’abord, elle permet d’améliorer la performance de vos applications en garantissant l’utilisation efficace des ressources du cluster et en réduisant les coûts de l’infrastructure, elle peut également améliorer la fiabilité et la disponibilité de vos applications en surveillant leur état et en redémarrant automatiquement les pods défaillants. Enfin, elle facilite la gestion de votre cluster en simplifiant la tâche de maintenance et de résolution des problèmes.
Pour résumer, en adoptant une approche d’optimisation continue de votre cluster Kubernetes, en comprenant les besoins de vos applications, en gérant efficacement les ressources, en appliquant les meilleures pratiques de sécurité et les astuces que nous avons présentées dans cet article, il est possible de tirer le meilleur parti de cette plateforme puissante.
Au final, une utilisation efficace de Kubernetes peut permettre aux entreprises de réaliser des économies de coûts, d’améliorer la disponibilité de leurs applications et de rester compétitives dans un monde en constante évolution.