
La performance demeure un facteur essentiel pour la plupart des applications livrées, et elle revêt une importance accrue pour les applications qui traitent une large quantité de données, où les développeurs auront besoin de faire le choix entre de multiples structures de données proposées par les différentes bibliothèques. Cet article présente les structures de données les plus utilisées par les développeurs .Net, ainsi que leurs comparaisons en termes de performance et leurs limites.
1-Les énumérables :
IEnumerable<T> est l’interface fondamentale pour itérer sur une collection d’objets, elle représente une séquence d’éléments à parcourir utilisant la boucle ForEach.
1-2-Considérations de performance :
Évaluation différée :
Afin de réaliser une meilleure gestion de mémoire lors de traitement de larges ensembles de données, les énumérables assurent une évaluation différée de ces données, en les récupérant à la demande.
L’évaluation différée des énumérables, ne concerne pas seulement la gestion du mémoire, il assure aussi un temps de chargement court, des interfaces responsives lors de provisionnement des données à afficher, ainsi que la flexibilité de composition et la manipulation des données.
L’exemple suivant présente l’évaluation différée de la liste des nombres pairs, où seulement un élément de cette liste est généré et traité à la fois et en fonction du besoin, ce qui améliorera considérablement les performances lors de traitements de grandes quantités des données.
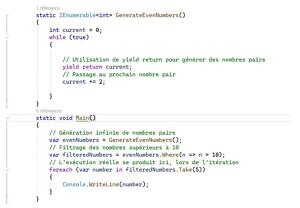
figure 1: Exemple d’évaluation différé des énumérables
Méthodes d’extension et LINQ
Le LINQ fournit plusieurs méthodes d’extension pour les énumérables ce qui permet de formuler des requêtes et des transformations expressives et utiles pour le traitement des données. L’exemple suivant présente une opération de filtrage et calcul de moyen grâce aux expressions LINQ :

Figure 2: Exemple des méthodes LINQ
Matérialisation :
Malgré leurs flexibilités, les énumérables ne sont pas suffisants pour implémenter tous types de manipulation sur les données, par exemple, si on a besoin de modifier un élément, on doit transformer l’énumérable en un tableau ou liste utilisant ToArrray() ou ToList(), ce processus est appelé matérialisation.
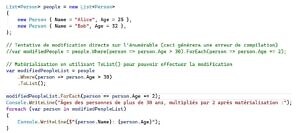
Figure 3: Exemple de matérialisation des énumérables
Dans l’exemple ci-dessus, le résultat d’expression « Where » est un énumérable, il est donc impossible d’appliquer des modifications sur ces éléments, et nous aurons besoin de la matérialiser en une liste.
Donc, pour effectuer certaines opérations qui exigent un accès direct aux éléments, comme la modification de la collection ou l’accès aléatoire à un élément, on doit matérialiser la séquence en une collection concrète. Il faut noter que la matérialisation des énumérables pourra avoir un impact sur la performance notamment pour les larges ensembles des données, car cela implique une copie de tous les éléments sur une nouvelle structure de données.
1-3-Les limites :
Accès séquentiel seulement :
Bien que les énumérables offrent un accès séquentiel aux éléments, elles ne permettent pas certaines opérations telles que l’accès direct par indice.
Lecture Seule :
Malgré la vaste possibilité de filtrer et gérer les données des énumérables grâce au LINQ, elles restent limitées à la lecture seulement, d’où le besoin de matérialiser la collection afin d’implémenter quelques opérations tel que l’ajout et la suppression.
Opération de transformation limitée :
Autre que l’indexation directe et la lecture et suppression des éléments à partir d’un énumérable, il y a aussi d’autres transformations de données tel que ToString() et substring() qui ne seront faits qu’après matérialisation d’énumérable en une liste or table.
2-Les Collections :
2-1-Définition et caractéristiques :
Les collections représentent l’implémentation concrète de diverses structures de données tel que List<T> et Dictionary<K, V> , elles occupent un espace de stockage de l’application pour sauvegarder les données et offrent une multitude d’opérations tel que la modification et l’accès par index.
2-2-Considérations et performance :
Accès aléatoire :
Les Collections, en particulier celles qui implémentent IList<T>, offrent un accès rapide et aléatoire aux éléments par indexation (par exemple, maListe[2]). Ce qui rend possible les scénarios où un accès direct aux éléments est important.
Opérations en mémoire :
Au cas où la quantité des données peut résider simplement dans la mémoire confortablement sans causer une surcharge, les collections seront la structure de données optimale pour les traiter car ils sont conçus pour le stockage et la manipulation des données en mémoire, ce qui facilite l’accès et rend rapide le traitement. Mais cela reste optimal pour la donnée de petite quantité.
Modification directe :
Les collections fournissent des méthodes pour la modification directe, ce qui peut être bénéfique pour les scénarios où les éléments doivent être ajoutés, supprimés ou modifiés fréquemment.
2-3-Limites :
Surcharge mémoire :
Les collections étant sauvegardées et manipulées dans la mémoire, cela peut causer une surcharge en cas de traitement en quantité.
Mutabilité :
La possibilité de modification, ajout et suppression des données d’une collection la rend susceptible des scénarios de conflit surtout dans des situations nécessitant l’immutabilité.
Moins efficaces pour de larges quantités de données :
Les collections deviennent une des solutions moins optimales en cas de traitement d’une large quantité de données, car de manière générale, les mémoires provisionnées aux applications ne sont pas assez larges.
3-Quérables :
3-1-Définition et caractéristiques :
IQueryable<T> représente une collection interrogeable des données, elle étend l’interface IEnumerable<T> en ajoutant la capacité de composer des requêtes qui peuvent être exécutées sur une source de données sous-jacente tel que SQL Server. Elle est fréquemment utilisée dans le contexte de LINQ to Entities avec Entity Framework comme décris dans la documentation suivante de Microsoft. Autrement, c’est une façon d’écrire des instructions LINQ qui seront traduites en requêtes SQL mais pas exécutées immédiatement.
3-2-Considérations de performance :
Exécution différée :
Il est vrai que l’exécution différée a été déjà présente avec les énumérables, est-il un aspect commun entre les énumérables et les interrogeables ( Queryable ) ? Oui, mais elle est partiellement différente avec les interrogeables, car elle prend en charge l’exécution différée au niveau de la source des données et non pas la mémoire de l’application. Cela permet la composition de requêtes complexes sans interaction immédiate avec la base des données, et l’exécution de requête sur la source de données ne prendra place que lorsqu’il y a de la demande de ces données pour plus de traitement en mémoire ou pour affichage.
L’exemple suivant présente l’exécution différée d’un interrogeable en C#.
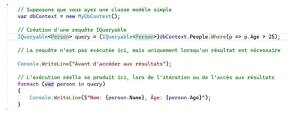
figure 4: Exemple d’évaluation différé des queryables
Arbres d’expression :
Les arbres d’expression sont des structures de données hiérarchiques représentant une expression (instruction) en format arborescent, les requêtes LINQ sont un exemple de ces instructions, ils seront transformés en requêtes optimisées par Entity Framework ou autres ORM. Cela permet des interactions plus efficaces avec la base des données en évitant l’exécution immédiate des opérations et le mixage du code avec les requêtes SQL.
L’exemple suivant montre la possibilité de créer des requêtes dynamiquement grâce aux arbres d’expression.
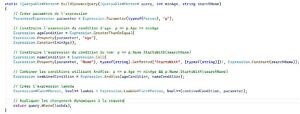
figure 5: Exemple des arbres d’expressions
La requête générée dynamiquement par l’exemple ci-dessus est la suivante :

Figure 6 : Exemple de requête générée par arbre d’expression
Les arbres d’expressions sont souvent utilisés pour représenter des expressions de requête LINQ, et les requêtes IQueryable exploitent ces arbres d’expressions pour permettre la création de requêtes flexibles qui peuvent être traduites efficacement en requêtes spécifiques à la source de données.
Optimisation des requêtes de base de données :
En permettant au fournisseur de données (Entity Framework, NHibernate…) d’analyser la structure de la requête, les objets interrogeables (Queryable) nous garantissent une génération de requêtes finales optimisées, sécurisées et efficaces. Cela assure aussi une réduction de la quantité des données transmises sur le réseau.
3-3-Limites
Dépendance à la base de données :
Les interrogeables ne sont pas adaptés aux scénarios de traitement des données au mémoire, ils dépendent des bibliothèques tel que Entity Framework pour les traduire en SQL et de la source des données qui prend en charge l’exécution de ces requêtes.
Complexité d’apprentissage :
La traduction des expressions LINQ en requêtes SQL et leurs exécutions, bien qu’elle soit faite en arrière-plan grâce aux bibliothèques tel que Entity Framework, est challengeante en tant que sujet d’apprentissage surtout dans les scénarios ou la performance est primordiale et le contrôle des requêtes doit être parfaitement optimisé, il faudrait revisiter les requêtes générées et s’assurer qu’ils ne présentent aucun souci ou mauvaise optimisation. La familiarité avec les sujets de LINQ To SQL , ainsi que les bibliothèques responsables de génération des requêtes est indispensable pour éviter les requêtes inefficaces et les problèmes de performance.
Difficulté de sérialisation :
C’est la difficulté de conversion des requêtes en une forme facilement stockée, transmise et utilisée dans des scénarios nécessitant la sérialisation à cause des expressions complexes ou de la dépendance étroite des interrogeables aux sources des données et à la bibliothèque assurant la traduction en SQL.
Conclusion
En résumé, le choix entre les trois structures de données dépend des exigences spécifiques de l’application développée. Il dépend également des caractéristiques des données et des opérations dont on a besoin d’effectuer. Nous devons aussi prendre en considération la gestion du mémoire, le besoin d’exécution différé et d’interaction avec la base des données.